漫画:深入浅出 ES 模块
本文来自网易云社区。
本文翻译自:ES modules: A cartoon deep-dive
ES 模块为 JavaScript 提供了官方标准化的模块系统。然而,这中间经历了一些时间 —— 近 10 年的标准化工作。
但等待已接近尾声。随着 5 月份 Firefox 60 发布(目前为 beta 版),所有主流浏览器都会支持 ES 模块,并且 Node 模块工作组也正努力在 Node.js 中增加 ES 模块支持。同时用于 WebAssembly 的 ES 模块集成 也在进行中。
许多 JavaScript 开发人员都知道 ES 模块一直存在争议。但很少有人真正了解 ES 模块的运行原理。
让我们来看看 ES 模块能解决什么问题,以及它们与其他模块系统中的模块有什么不同。
模块要解决什么问题?
可以这样说,JavaScript 编程就是管理变量。所做的事就是为变量赋值,或者在变量上做加法,或者将两个变量组合在一起并放入另一个变量中。
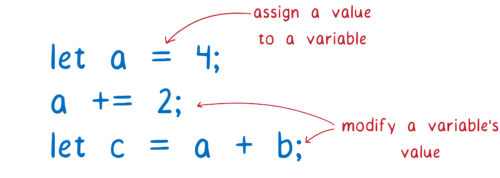
因为你的代码中很多都是关于改变变量的,你如何组织这些变量会对你编码方式以及代码的可维护性产生很大的影响。
一次只需要考虑几个变量就可以让事情变得更简单。JavaScript 有一种方法可以帮助你做到这点,称为作用域。由于 JavaScript 中的作用域规则,一个函数无法访问在其他函数中定义的变量。
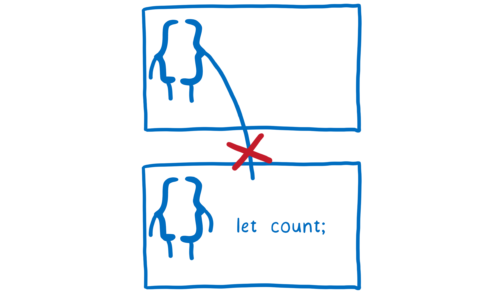
这很好。这意味着当你写一个函数时,只需关注这个函数本身。你不必担心其他函数可能会对函数内的变量做些什么。
尽管如此,它仍然存在缺陷。这让在函数间共享变量变得有点困难。
如果你想在作用域外共享变量呢?处理这个问题的一种常见方法是将它放在更外层的作用域里……例如,在全局作用域中。
你可能还记得 jQuery 时代的这种情况。在加载任何 jQuery 插件之前,你必须确保 jQuery 在全局作用域中。
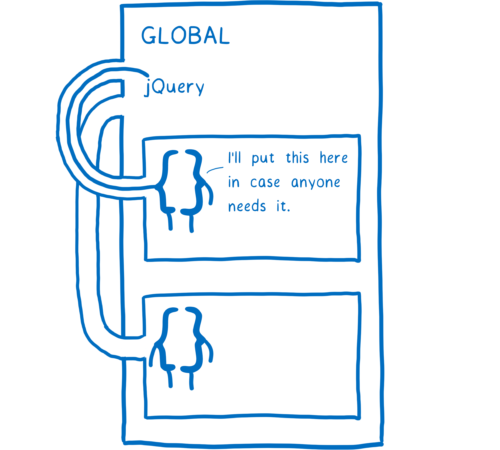
这在有效的同时也产生了副作用。
首先,所有的 script 标签都需要按照正确的顺序排列。所以你必须小心确保那个顺序没被打乱。
如果你搞乱了这个顺序,那么在运行的过程中,你的应用程序就会抛出一个错误。当函数寻找它期望的 jQuery 时 —— 在全局作用域里 —— 却没有找到它,它会抛出一个错误并停止运行。

这使得维护代码非常棘手。这让移除老代码或老 script 标签变成了一场轮盘赌游戏。你不知道会弄坏什么。代码的不同部分之间的依赖关系是隐式的。任何函数都可以获取全局作用域中的任何东西,所以你不知道哪些函数依赖于哪些 script 标签。
第二个问题是,因为这些变量位于全局范围内,所以全局范围内的代码的每个部分都可以更改该变量。恶意代码可能会故意更改该变量,以使你的代码执行某些你并不想要的操作,或者非恶意代码可能会意外地弄乱你的变量。
模块是如何提供帮助的?
模块为你提供了更好的方法来组织这些变量和函数。通过模块,你可以将有意义的变量和函数分组在一起。
这会将这些函数和变量放入模块作用域。模块作用域可用于在模块中的函数之间共享变量。
但是与函数作用域不同,模块作用域也可以将其变量提供给其他模块。它们可以明确说明模块中的哪些变量、类或函数应该共享。
当将某些东西提供给其他模块时,称为 export。一旦你声明了一个 export,其他模块就可以明确地说它们依赖于该变量、类或函数。
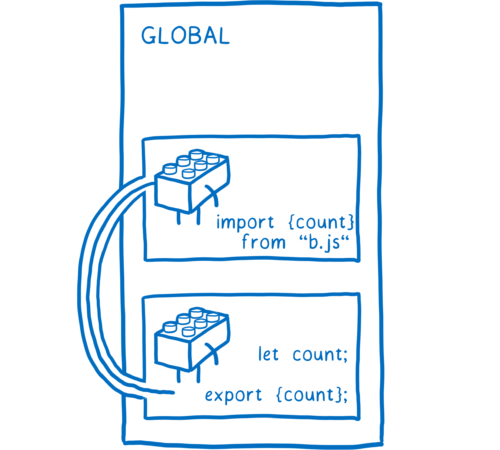
因为这是显式的关系,所以当删除了某个模块时,你可以确定哪些模块会出问题。
一旦你能够在模块之间导出和导入变量,就可以更容易地将代码分解为可独立工作的小块。然后,你可以组合或重组这些代码块(像乐高一样),从同一组模块创建出各种不同的应用程序。
由于模块非常有用,历史上有多次向 JavaScript 添加模块功能的尝试。如今有两个模块系统正在大范围地使用。CommonJS(CJS)是 Node.js 历史上使用的。ESM(EcmaScript 模块)是一个更新的系统,已被添加到 JavaScript 规范中。浏览器已经支持了 ES 模块,并且 Node 也正在添加支持。
让我们来深入了解这个新模块系统的工作原理。
ES 模块如何工作?
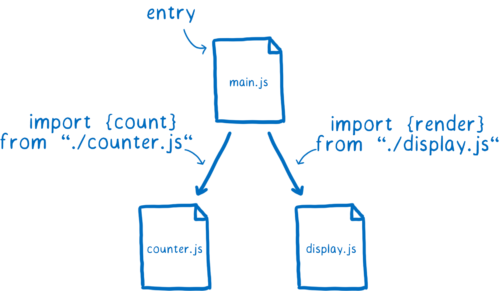
使用模块开发时,会建立一个依赖图。不同依赖项之间的连接来自你使用的各种 import 语句。
浏览器或者 Node 通过 import 语句来确定需要加载什么代码。你给它一个文件来作为依赖图的入口。之后它会随着 import 语句来找到所有剩余的代码。
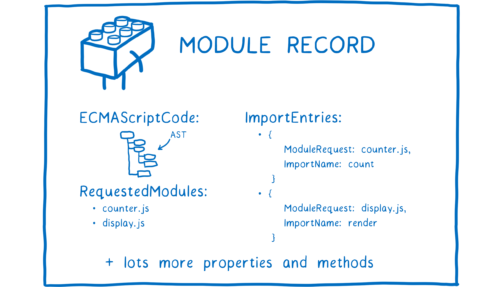
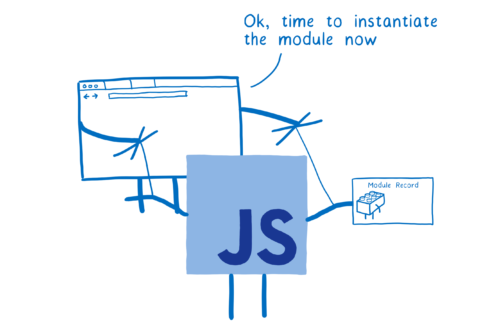
但浏览器并不能直接使用文件本身。它需要把这些文件解析成一种叫做模块记录(Module Records)的数据结构。这样它就知道了文件中到底发生了什么。
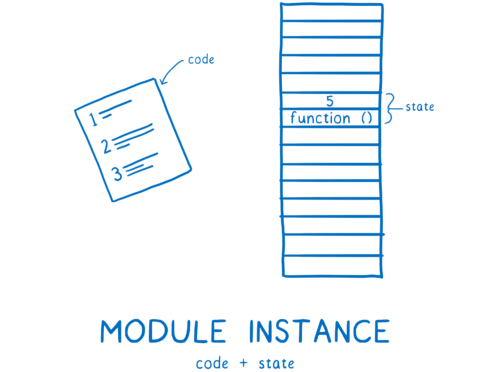
之后,模块记录需要转化为模块实例(module instance)。一个实例包含两个部分:代码和状态。
代码基本上是一组指令。就像是一个告诉你如何制作某些东西的配方。但你仅依靠代码并不能做任何事情。你需要将原材料和这些指令组合起来使用。
什么是状态?状态就是给你这些原材料的东西。指令是所有变量在任何时间的实际值的集合。当然,这些变量只是内存中保存值的数据块的名称而已。
所以模块实例将代码(指令列表)和状态(所有变量的值)组合在一起。
我们需要的是每个模块的模块实例。模块加载就是从此入口文件开始,生成包含全部模块实例的依赖图的过程。
对于 ES 模块来说,这主要有三个步骤:
- 构造 —— 查找、下载并解析所有文件到模块记录中。
- 实例化 —— 在内存中寻找一块区域来存储所有导出的变量(但还没有填充值)。然后让 export 和 import 都指向这些内存块。这个过程叫做链接(linking)。
- 求值 —— 运行代码,在内存块中填入变量的实际值。
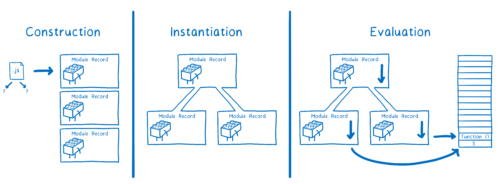
人们说 ES 模块是异步的。你可以把它当作时异步的,因为整个过程被分为了三阶段 —— 加载、实例化和求值 —— 这三个阶段可以分开完成。
这意味着 ES 规范确实引入了一种在 CommonJS 中并不存在的异步性。我稍后会再解释,但是在 CJS 中,一个模块和其下的所有依赖会一次性完成加载、实例化和求值,中间没有任何中断。
当然,这些步骤本身并不必须是异步的。它们可以以同步的方式完成。这取决于谁在做加载这个过程。这是因为 ES 模块规范并没有控制所有的事情。实际上有两部分工作,这些工作分别由不同的规范控制。
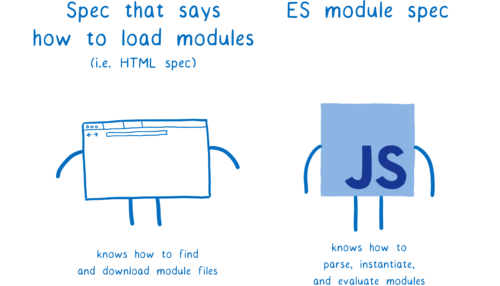
ES模块规范说明了如何将文件解析到模块记录,以及如何实例化和求值该模块。但是,它并没有说明如何获取文件。
是加载器来获取文件。加载器在另一个不同的规范中定义。对于浏览器来说,这个规范是 HTML 规范。但是你可以根据所使用的平台有不同的加载器。
加载器还精确控制模块的加载方式。它调用 ES 模块的方法 —— ParseModule、Module.Instantiate 和 Module.Evaluate。这有点像通过提线来控制 JS 引擎这个木偶。
现在让我们更详细地介绍每一步。
构造
在构造阶段,每个模块都会经历三件事情。
- 找出从哪里下载包含该模块的文件(也称为模块解析)
- 获取文件(从 URL 下载或从文件系统加载)
- 将文件解析为模块记录
查找文件并获取
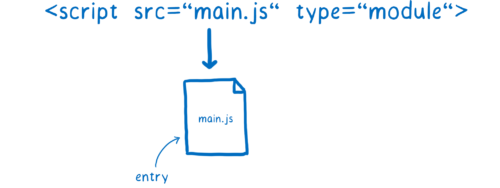
加载器将负责查找文件并下载它。首先它需要找到入口文件。在 HTML 中,你通过使用 script 标记来告诉加载器在哪里找到它。
但它如何找到剩下的一堆模块 —— 那些 main.js 直接依赖的模块?
这就要用到 import 语句了。import 语句中的一部分称为模块标识符。它告诉加载器哪里可以找到余下的模块。

关于模块标识符有一点需要注意:它们有时需要在浏览器和 Node 之间进行不同的处理。每个宿主都有自己的解释模块标识符字符串的方式。要做到这一点,它使用了一种称为模块解析的算法,它在不同平台之间有所不同。目前,在 Node 中可用的一些模块标识符在浏览器中不起作用,但这个问题正在被修复。
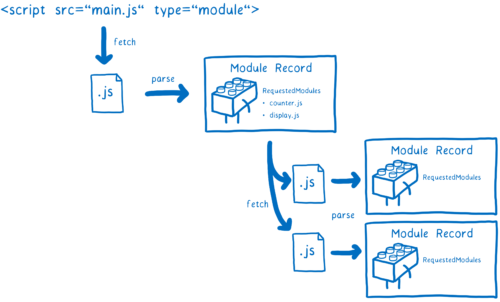
在修复之前,浏览器只接受 URL 作为模块标识符。它们将从该 URL 加载模块文件。但是,这并不是在整个依赖图上同时发生的。在解析文件前,并不知道这个文件中的模块需要再获取哪些依赖……并且在获取文件之前无法解析那个文件。
这意味着我们必须逐层遍历依赖树,解析一个文件,然后找出它的依赖关系,然后查找并加载这些依赖。
如果主线程要等待这些文件的下载,那么很多其他任务将堆积在队列中。
这是就是为什么当你使用浏览器时,下载部分需要很长时间。
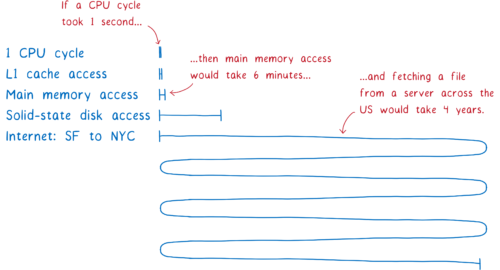
基于此图表。
像这样阻塞主线程会让采用了模块的应用程序速度太慢而无法使用。这是 ES 模块规范将算法分为多个阶段的原因之一。将构造过程单独分离出来,使得浏览器在执行同步的初始化过程前可以自行下载文件并建立自己对于模块图的理解。
这种方法 —— 将算法分解成不同阶段 —— 是 ES 模块和 CommonJS 模块之间的主要区别之一。
CommonJS 可以以不同的方式处理的原因是,从文件系统加载文件比在 Internet 上下载需要少得多的时间。这意味着 Node 可以在加载文件时阻塞主线程。而且既然文件已经加载了,直接实例化和求值(在 CommonJS 中并不区分这两个阶段)就理所当然了。这也意味着在返回模块实例之前,你遍历了整棵树,加载、实例化和求值了所有依赖关系。
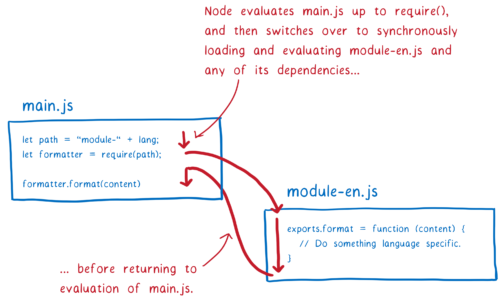
CommonJS 方法有一些隐式特性,稍后我会解释。其中一个是,在使用 CommonJS 模块的 Node 中,可以在模块标识符中使用变量。在查找下一个模块之前,你执行了此模块中的所有代码(直至 require 语句)。这意味着当你去做模块解析时,变量会有值。
但是对于 ES 模块,在进行任何求值之前,你需要事先构建整个模块图。这意味着你的模块标识符中不能有变量,因为这些变量还没有值。

但有时候在模块路径使用变量确实非常有用。例如,你可能需要根据代码的运行情况或运行环境来切换加载某个模块。
为了让 ES 模块支持这个,有一个名为 动态导入 的提案。有了它,你可以像 import(`${path}`/foo.js 这样使用 import 语句。
它的原理是,任何通过 import() 加载的的文件都会被作为一个独立的依赖图的入口。动态导入的模块开启一个新的依赖图,并单独处理。
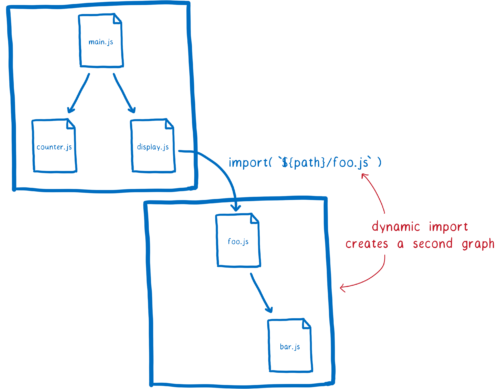
有一点需要注意,同时存在于这两个依赖图中的模块都将共享同一个模块实例。这是因为加载器会缓存模块实例。对于特定全局作用域中的每个模块,都将只有一个模块实例。
这意味着引擎的工作量减少了。例如,这意味着即使多个模块依赖某个模块,这个模块的文件也只会被获取一次。(这是缓存模块的一个原因,我们将在求值部分看到另一个。)
加载器使用一种叫做模块映射的东西来管理这个缓存。每个全局作用域都在一个单独的模块映射中跟踪其模块。
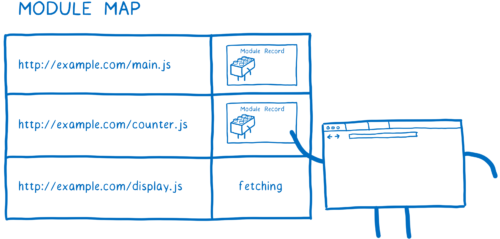
当加载器开始获取一个 URL 时,它会将该 URL 放入模块映射中,并标记上它正在获取文件。然后它会发出请求并继续开始获取下一个文件。

如果另一个模块依赖于同一个文件会发生什么?加载器将查找模块映射中的每个 URL。如果看到了 fetching,它就会直接开始下一个 URL。
但是模块映射不只是跟踪哪些文件正在被获取。模块映射也可以作为模块的缓存,接下来我们就会看到。
解析
现在我们已经获取了这个文件,我们需要将它解析为模块记录。这有助于浏览器了解模块的不同部分。
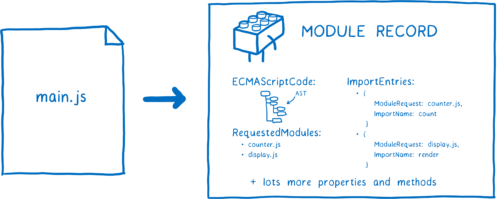
一旦模块记录被创建,它会被记录在模块映射中。这意味着在这之后的任意时间如果有对它的请求,加载器就可以从映射中获取它。
解析中有一个细节可能看起来微不足道,但实际上有很大的影响。所有的模块都被当作在顶部使用了 "use strict" 来解析。还有一些其他细微差别。例如,关键字 await 保留在模块的顶层代码中,this 的值是 undefined。
这种不同的解析方式被称为「解析目标」。如果你使用不同的目标解析相同的文件,你会得到不同的结果。所以在开始解析你想知道正在解析的文件的类型 —— 它是否是一个模块。
在浏览器中这很容易。你只需在 script 标记中设置 type="module"。这告诉浏览器此文件应该被解析为一个模块。另外由于只有模块可以被导入,浏览器也就知道任何导入的都是模块。
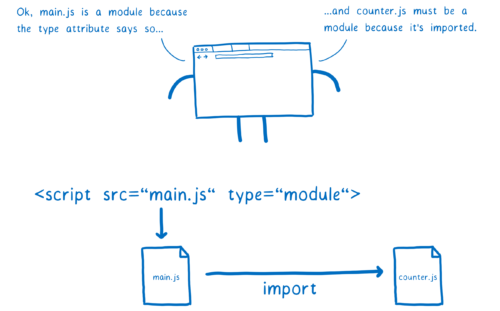
但是在 Node 中,不使用 HTML 标签,所以没法选择使用 type 属性。社区试图解决这个问题的一种方法是使用 .mjs 扩展名。使用该扩展名告诉 Node「这个文件是一个模块」。你会看到人们将这个叫做解析目标的信号。讨论仍在进行中,所以目前还不清楚 Node 社区最终会决定使用什么信号。
无论哪种方式,加载器会决定是否将文件解析为模块。如果是一个模块并且有导入,则加载器将再次启动该过程,直到获取并解析了所有的文件。
我们完成了!在加载过程结束时,从只有一个入口文件变成了一堆模块记录。
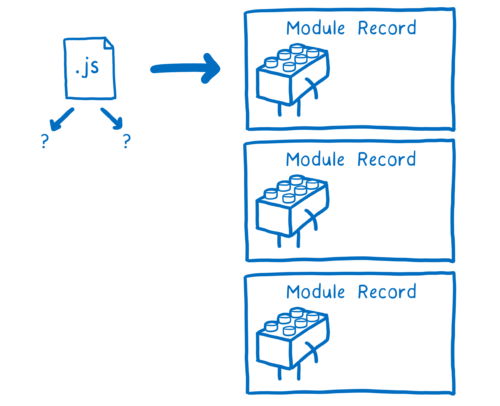
下一步是实例化此模块并将所有实例链接在一起。
实例化
就像我之前提到的,实例将代码和状态结合起来。状态存在于内存中,因此实例化步骤就是将内容连接到内存。
首先,JS 引擎创建一个模块环境记录(module environment record)。它管理模块记录对应的变量。然后它为所有的 export 分配内存空间。模块环境记录会跟踪不同内存区域与不同 export 间的关联关系。
这些内存区域还没有被赋值。只有在求值之后它们才会获得真正的值。这条规则有一点需要注意:任何 export 的函数声明都在这个阶段初始化。这让求值更加容易。
为了实例化模块图,引擎将执行所谓的深度优先后序遍历。这意味着它会深入到模块图的底部 —— 直到不依赖于其他任何东西的底部 —— 并处理它们的 export。
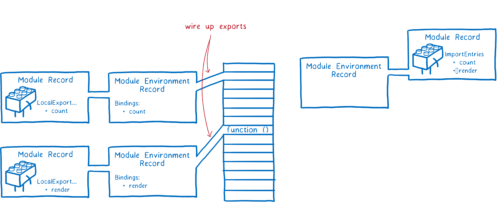
引擎将某个模块下的所有导出都连接好 —— 也就是这个模块所依赖的所有导出。之后它回溯到上一层来连接该模块的所有导入。
请注意,导出和导入都指向内存中的同一个区域。先连接导出保证了所有的导出都可以被连接到对应的导入上。
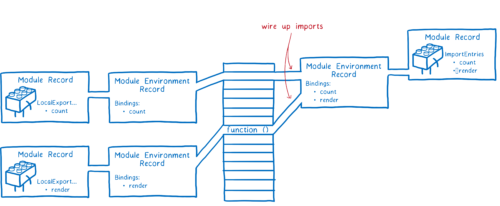
这与 CommonJS 模块不同。在 CommonJS 中,整个 export 对象在 export 时被复制。这意味着 export 的任何值(如数字)都是副本。
这意味着如果导出模块稍后更改该值,则导入模块并不会看到该更改。
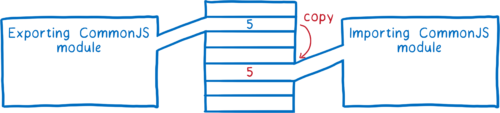
相比之下,ES 模块使用叫做动态绑定(live bindings)的东西。两个模块都指向内存中的相同位置。这意味着当导出模块更改一个值时,该更改将反映在导入模块中。
导出值的模块可以随时更改这些值,但导入模块不能更改其导入的值。但是,如果一个模块导入一个对象,它可以改变该对象上的属性值。
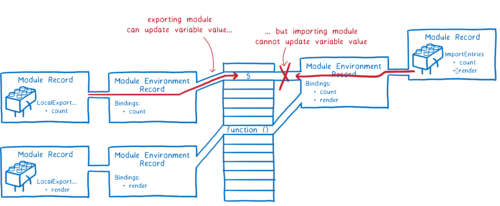
之所以使用动态绑定,是因为这样你就可以连接所有模块而不需要运行任何代码。这有助于循环依赖存在时的求值,我会在下面解释。
因此,在此步骤结束时,我们将所有实例和导出 / 导入变量的内存位置连接了起来。
现在我们可以开始求值代码并用它们的值填充这些内存位置。
求值
最后一步是在内存中填值。JS 引擎通过执行顶层代码 —— 函数之外的代码来实现这一点。
除了在内存中填值,求值代码也会引发副作用。例如,一个模块可能会请求服务器。

由于潜在的副作用,你只想对模块求值一次。对于实例化中发生的链接过程,多次链接会得到相同的结果,但与此不同的是,求值结果可能会随着求值次数的不同而变化。
这是需要模块映射的原因之一。模块映射通过规范 URL 来缓存模块,所以每个模块只有一个模块记录。这确保了每个模块只会被执行一次。就像实例化一样,这会通过深度优先后序遍历完成。
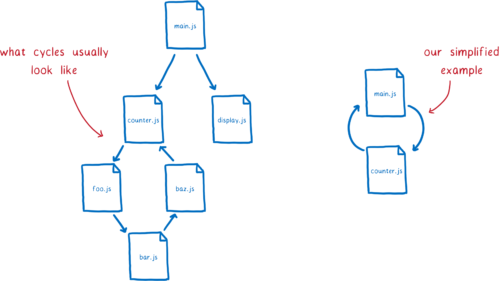
那些我们之前谈过的循环依赖呢?
如果有循环依赖,那最终会在依赖图中产生一个循环。通常,会有一个很长的循环路径。但为了解释这个问题,我打算用一个短循环的人为的例子。
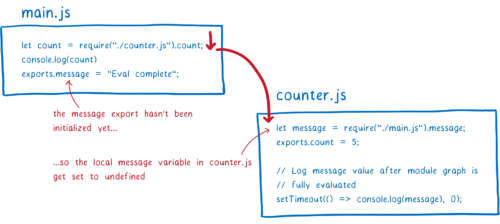
让我们看看 CommonJS 模块如何处理这个问题。首先,main 模块会执行到 require 语句。然后它会去加载 counter 模块。
然后 counter 模块会尝试从导出对象访问 message。但是,由于这尚未在 main 模块中进行求值,因此将返回 undefined。JS 引擎将为局部变量分配内存空间并将值设置为 undefined。

求值过程继续,直到 counter 模块顶层代码的结尾。我们想看看最终是否会得到正确的 message 值(在 main.js 求值之后),因此我们设置了 timeout。之后在 main.js 上继续求值。
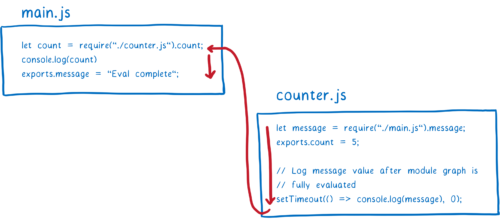
message 变量将被初始化并添加到内存中。但是由于两者之间没有连接,它将在 counter 模块中保持 undefined。
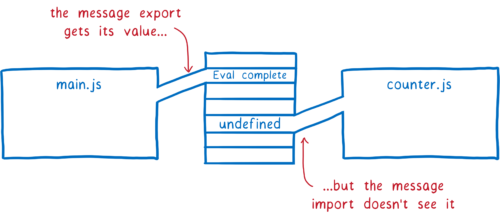
如果使用动态绑定处理导出,则 counter 模块最终会看到正确的值。在 timeout 运行时,main.js 的求值已经结束并填充了该值。
支持这些循环依赖是 ES 模块设计背后的一大缘由。正是这种三段式设计使其成为可能。
ES 模块的现状如何?
随着 5 月初会发布的 Firefox 60,所有主流浏览器均默认支持 ES 模块。Node 也增加了支持,一个工作组正致力于解决 CommonJS 和 ES 模块之间的兼容性问题。
这意味着你可以在 script 标记中使用 type=module,并使用 import 和 export。但是,更多模块特性尚未实现。动态导入提议正处于规范过程的第 3 阶段,有助于支持 Node.js 用例的 import.meta 也一样,模块解析提议也将有助于抹平浏览器和 Node.js 之间的差异。所以我们可以期待将来的模块支持会更好。
致谢
感谢所有对这篇文章给予反馈意见,或者通过书面和讨论提供信息的人,包括 Axel Rauschmayer、Bradley Farias、Dave Herman、Domenic Denicola、Havi Hoffman、Jason Weathersby、JF Bastien、Jon Coppeard、Luke Wagner、Myles Borins、Till Schneidereit、Tobias Koppers 和 Yehuda Katz,也感谢 WebAssembly 社区组、Node 模块工作组和 TC39 的成员们。
关于 Lin Clark
Lin 是 Mozilla 开发者关系组的一名工程师。她研究 JavaScript、WebAssembly、Rust 和 Servo,也画过一些代码漫画。
本文已由作者授权网易云社区发布,未经允许不得转载。