正则表达式学习[2021年1月29日15:38:40]
正则表达式
常用正则表达式的网址:http://tool.chinaz.com/regex/
第二个网址:https://www.cnblogs.com/bigtreei/p/7826894.html
一:正则表达式是什么
正则表达 regular expression(有规律的 表达 )
测试字符串的某个模式。例如,可以测试字符串是否存在一个电话号码模式或email格式。这称为数据有效性验证
替换文本。可以在文档中使用一个正则表达式来标识特定文字,然后可以全部将其删除,或者替换为别的文字
根据模式匹配从字符串中提取一个子字符串。可以用来在文本或输入字段中查找特定文字
二:正则表达式的基础语法
一个正则表达式就是由普通字符(例如字符 a 到 z)以及特殊字符(称为元字符)组成的文字模式。
该模式描述在查找文字主体时待匹配的一个或多个字符串。
正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
创建正则表达式
var re = new RegExp(); //RegExp是一个对象,和Array一样 ,但这样没有任何效果,需要将正则表达式的内容作为字符串传递进去
re =new RegExp("a");//最简单的正则表达式,将匹配字母a
re=new RegExp("a","i");//第二个参数,表示匹配时不分大小写
三:正则表达式有哪些
1:方口号[]
[abc]查找方括号中的任何字符
[^abc]匹配任何不在方括号的字符
[0-9]匹配0-9的字符
a-z] 匹配任何从小写 a 到小写 z 的字符
[A-Z] 匹配任何从大写 A 到大写 Z 的字符
[A-z] 匹配任何从大写 A 到小写 z 的字符
--**--放到中括号里会取消他得特殊意义有
. : | []()
2:小括号
用于匹配分组
/(ab|cd)+|ef/ 匹配字符串"ab" 或者 "cd" 的一次或多次重复. 也可以是字符串 "ef",
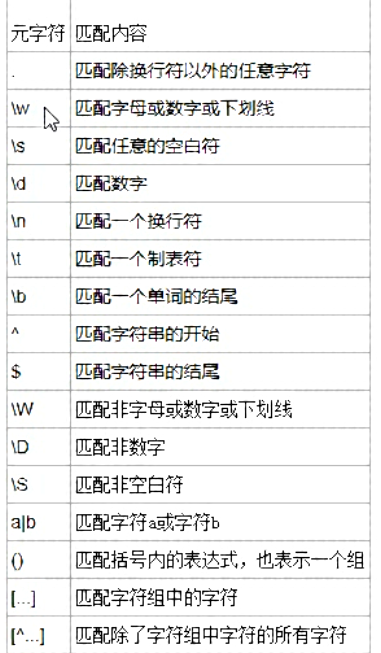
3:元字符(Metacharacter)是拥有特殊含义的字符:
----------重要的元字符--------
. 查找单个字符,除了换行和行结束符
\w 匹配字母数字和下划线w-->word \W [^a-zA-Z0-9_] 匹配 除 字母数字下划线之外的字符
\d 匹配数字 d-->digit \D [^0-9] 匹配 非 数字字符
\s 匹配一个空白字符包含了[\n\r\t\f\x0B] \S [^\n\r\t\f\x0B] 匹配一个 非 空白字符
\b 匹配单词的边界 \B 匹配 非 单词边界
---------位置限制符------
^ 匹配任何开头为的字符串 例如 ,^n 匹配任何开头为 n 的字符串
$ 匹配任何结尾为的字符串 例如 ,n$ 匹配任何结尾为 n 的字符串
-------------------------------------------
\n 匹配 换行符
\r 匹配 回车符
\t 匹配 制表符
\f 匹配 换页符
\x0B
\xxx 查找以八进制数 xxx 规定的字符
\0 匹配 NUL 字符
\v 匹配 垂直制表符
------------直接量字符----------------
\/ 匹配 /
\\ 匹配 \
\. 匹配 .
\* 匹配 *
\+ 匹配 +
\? 匹配 ?
\| 匹配 |
\( 匹配 (
\) 匹配 )
\[ 匹配 [
\] 匹配 ]
\{ 匹配 {
\ } 匹配 }
\’ 匹配 单引号
\” 匹配 双引号
\xxx 查找以八进制数 xxx 规定的字符
\xdd 查找以十六进制数 dd 规定的字符
\uxxxx 查找以十六进制数 xxxx 规定的 Unicode 字符
----------量词--------
{n} 表示这个量词之前出现的字符出现n次
{n,}表示这个量词之前出现的字符至少出现n次
{n,m}表示这个量词之前出现的字符至少出现n-m次
?表示匹配量词之前的字符出现0词或者1词 表示可有可无
+ 表示匹配量词之前的字符出现1次或多次
* 表示匹配量词之前的字符出现0次或是多次
四:重要的例子案例
1:匹配一个手机号11位,第一位固定是1,第二位是4-9 -----> 1[4-9]\d{9}
2:匹配一个整数----------> \d+
3:匹配一个小数---------> \d+\.\d+
4:匹配小数,匹配整数------> \d+\.\d+|\d+ ----第二个答案---->变成\d+(\.\d+)?
5:身份证是一个长度15或18位的字符串,如果是15则全部为数字组成,末尾不能为0;
如果是18位,则前面17位全部为数字,末尾可能是数字或X,下面我们用正则表达式来表示
1:[1-9]\d{16}[\dx]|[1-9]\d{14}
2:[1-9]\d{14}(\d{2}[\dx])?
五:知识点:
()分组 表示给几个字符加上量词约束的需求的时候,就给这些量词分在一个组
匹配小数,匹配整数------> \d+\.\d+|\d+ ----第二个答案---->变成\d+(\.\d+)?
六:几个常用的非贪婪匹配Pattern
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
重点
关于字符串放发哦PythOn的转移问题,
只需要在python中的字符串外面加上r,r''
总结内容2021年1月29日15:25:26
1:什么是模块
2:什么是正则表达式
元字符:\d \w \s \n \t \b \W \D \S . ^ $ [] [^] | ()
量词:? + * {n}{n,}{n,m}
贪婪匹配/惰性匹配 默认贪婪/量词? 惰性匹配
普通字符就表示一个正常的字符
元字符表示它的特殊的意义,如果转义元字符,那么这个元字符就失去了意义
3:几个字符的组合
字符/元字符 只约束一个字符
字符+量词 约束一个字符连续出现的次数
字符+量词+? 约束一个字符连续出现的最少次数
字符+量词+?+x 约束一个字符连续出现的量词范围内的最少次数遇到x就立即停止
版权声明:本文为suhuojin原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。