StableDiffusion基本功能解释
StableDiffusion基本功能
介绍SDWbeUI的页面布局、快捷栏设置、VAE简介、图片信息、描述语、模型选择管理、模版风格、采样方法、步数/面部/平铺、高清修复、批次与数量、CFGscale、随机种子、差异随机种子、模型选择。首先需要安装中英双语插件,方便我们识别请看这篇文章:中文汉化
开启VAE
首先我们需要加载VAE选项,就需要在设置中把这个功能打开。VAE的功能是一张图片生成出来的一个滤镜或光影的感觉。有些图画出来是雾蒙蒙的感觉,就是没有加载VAE的内容导致的。有些人画的图雾蒙蒙的就是没有它。如下图所示,左边是没有加载VEA,右侧是加载了的。

同时我们在civitai下载模型的时候,也有下载VAE选项,我们也要下载。如果没有就是被内置进去了,我们就不用下载了。(大部分是内置的)
VAE模型的路径是 \models\VAE
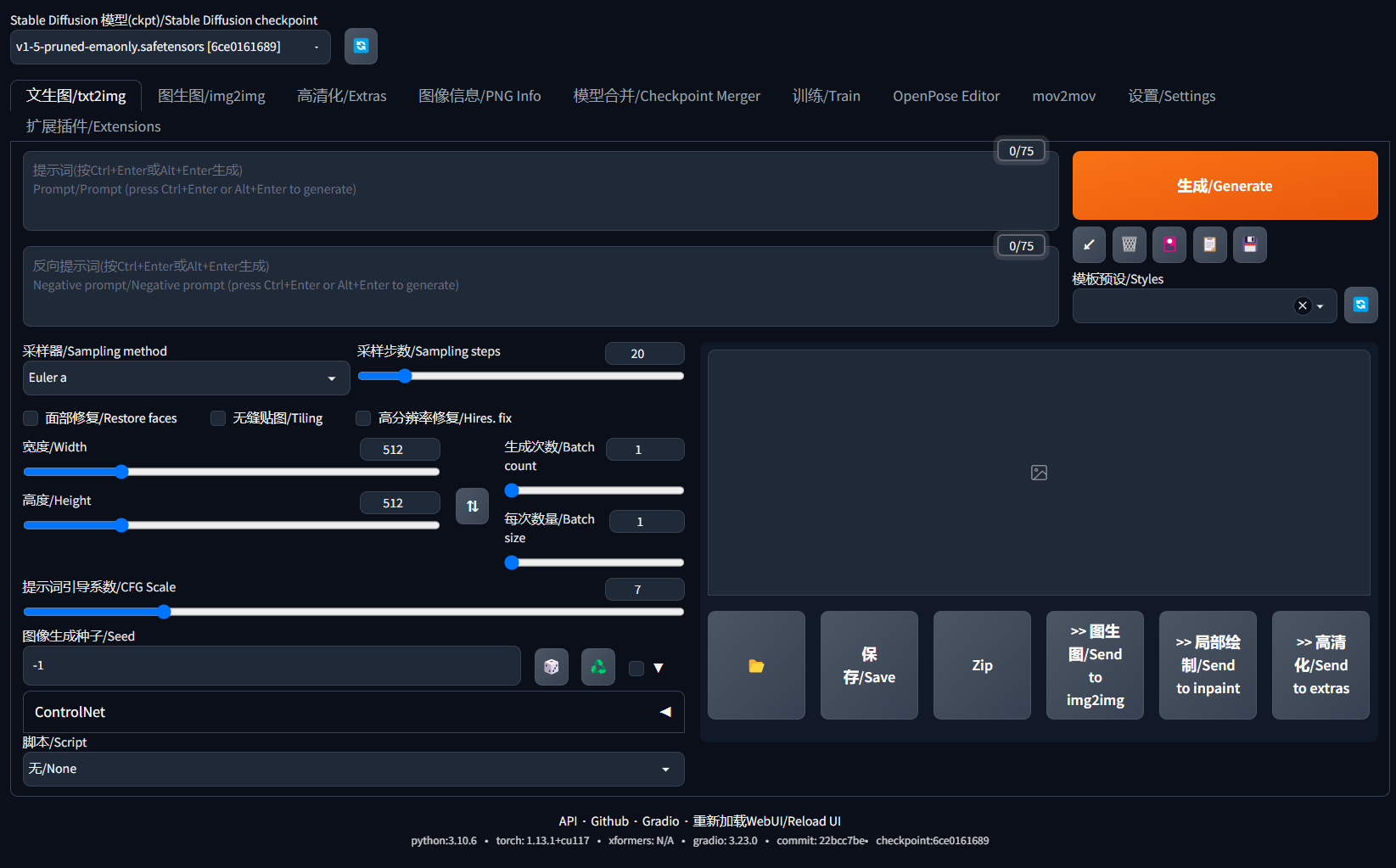
点击设置–用户界面–快捷设置列表 填写如下内容
sd_model_checkpoint,sd_vae
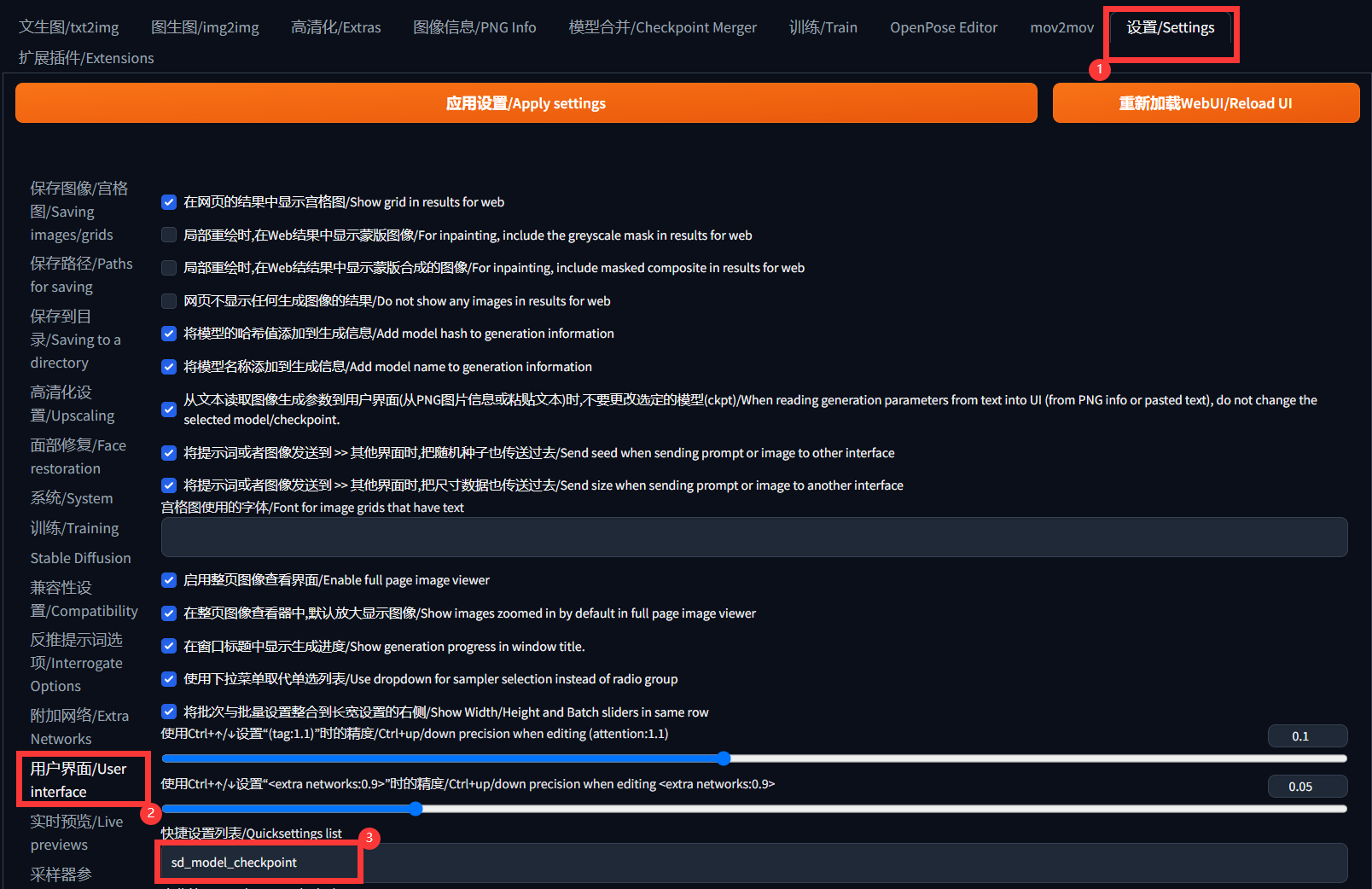
填写好后,点击应用设置–重新加载

重新启动后,我们就可以看到顶部的VAE选项已经出现了。
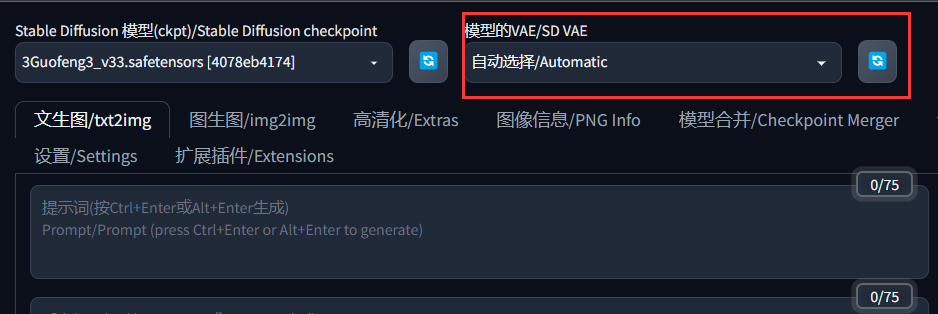
功能介绍
文生图:顾名思义,通过文字生成图片
图生图:添加参考图根据要求再生成图片
高清化:放大图片像素或批量处理图片的功能

图片信息:可以把别人的图拖进去获取到图片提示词信息,前提必需是别人没有处理掉信息且还是SD生成的图片。自己做的图也能拖进去获取到图片信息。
混合模型:可以把两个模型合成一个,变成混合模型

正向描述语和反向描述语:正向代表想要的图片效果,反向代表不想要的图片效果。它和Midjourney的prompt很像,输入关键词即可,和ChatGPT的提示词不同,它是没有语言前后判断,只需要输入单词就可以。
提示词规则
逗号:每个词语用英文逗号间隔,
括号:代表权重(blurry background) 一个括号代表1.1倍权重,((blurry background) )两个代表1.1*1.1倍权重,通常都会这样表示权重倍数(blurry background:1.2) 直接书写权重值,后面加了:1.2 就直接表示1.2倍权重了。
功能解释
信息框按钮
这个箭头图标代表读取你上一张图片信息提示词

垃圾桶是清空提示词的意思,点击后直接清空左侧输入的提示词信息
这个相当于是一个模型图形选择页面,可以自由管理模型的分类方便整理选择,适合模型非常多且乱的情况,就可以在里面管理我们的模型文件了。

这个是重新加载输入框

当你想保存自己的基础提示词模版的时候,就可以点击保存一下。在下方的模版预设中选择你之前保存的提示词信息后,它就会按照你之前的基础上进行生成了。例如,我每次都是要生成的词是1girl反向是worst quality那么我就可以保存一下,下次直接选择这些基础的模版提示词进行生成图像了,节省了我们每次得输入大量基础的提示词的疼点问题。
当你保存后,它会在你的根目录中,是一个.csv文件,如果想要修改里面的内容,请用记事本的方式打开修改。
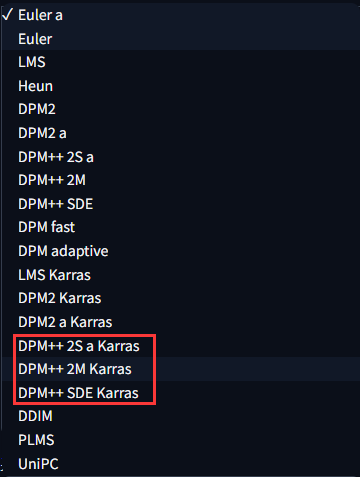
采样方法
它是不同的生成模式,需要自己对比看效果。
采样步数/Sampling steps:通过多少步骤把图画出来,一般情况设置20-30就够用了,除非你的描述语很复杂画面非常复杂,否则步数再多反而效果不好。

面部修复
面部修复:画写实人物的时候几乎是必选的,面部会画的更细致。画动漫二次元效果就不会很明显。选择后会占用一些显存。
平铺/分块:我很少用,因为效果不好,图片容易很奇怪。

高清修复
把你基础的图片,按照你的设置,进行放大倍率,再次按照你放大的图片再进行重绘。
高清算法/UPscaler:这个一般默认选一个,其他大家自己测试。它和前面说的采样样式有些类似,可以试试选择自己喜欢的就好。
高分辨率采样步数/Hiressteps:通常选择10-20即可。
重绘幅度:设置的越高,变化的越大,细节也会增加很多,设置的越少重绘幅度越小。
放大倍率:它是按照你原尺寸乘以这个倍数,设置的越高图片越精细,尺寸越大,算图的时间也会增长。
将宽度调整到和高度调整到:它和放大倍率是同一种功能,一个是用倍数一个具体参数,两个只能选择一种方式放大。
生成批次
代表生成多少次,和每次多少张。如果选择2次和两张图,那么加起来就是4张图,分两次生成,每次两张。
提示词引导
提示词引导:通常设置7-15左右。低于7图片会糊,高于15出现很多奇怪细节太多。
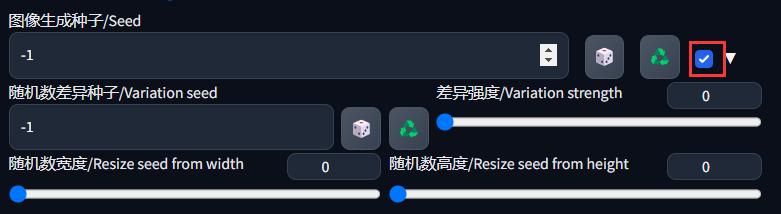
种子
每张图都有它的种子,你生成的图片也有它的种子,别人的也有。你复制别人的或者自己的种子放进去,就会生成类似的图片。但是它是和尺寸有关联得,尺寸对应不上种子之间就不会出现相似度。
随机种子有点像图片的DNA,而这个数值只有它自己能知道这个数值的图片分布情况。可以复制别人的,自己的图也能生成种子,通常种子是拿来绘制同一种场景布局时常会使用。种子的数值不同也会影响图片的布局情况。-1代表每次生成使用随机种子。
在图片分辨率不改动的情况下,哪怕你切换模型,或者改了一些其他参数,你生成的图像大致的构图结构,会和你的种子类似。如果改了尺寸,那么图就会完全变了。
骰子:使用随机种子
循环图标:填写最近生成的种子值

差异随机种子
勾选后就会出现一个选项框,这个就是类似于用两种种子进行混合的方式。
用你差异的种子去和图片种子分配权重,差异强度代表差异种子的权重,通常用作同一种风格,生成不同类型构图的图片使用的功能
模型
checkpoint模型
比较大,至少2G起步,它代表基础模型。在civitai下载模型的时候会有这个提示的。
基础模型相当于你画这张图基于这个大的数据库保证这张图的质量;基础模型只能选择一个。

Lora模型
是需要放在指定的Lora文件夹里面的模型,它一般不会超过150M的大小。它是一个新鲜模型,可以对画面进行微调,比如说固定一张脸,固定一个风格,固定画面中的一些细节内容的。比如一个衣服的Lora,每次生成它都会穿同一件衣服,以及人脸也是一样的。
就像很多老司机生成的图片,他们都是套用一个人脸的Lora,就是这个意思。

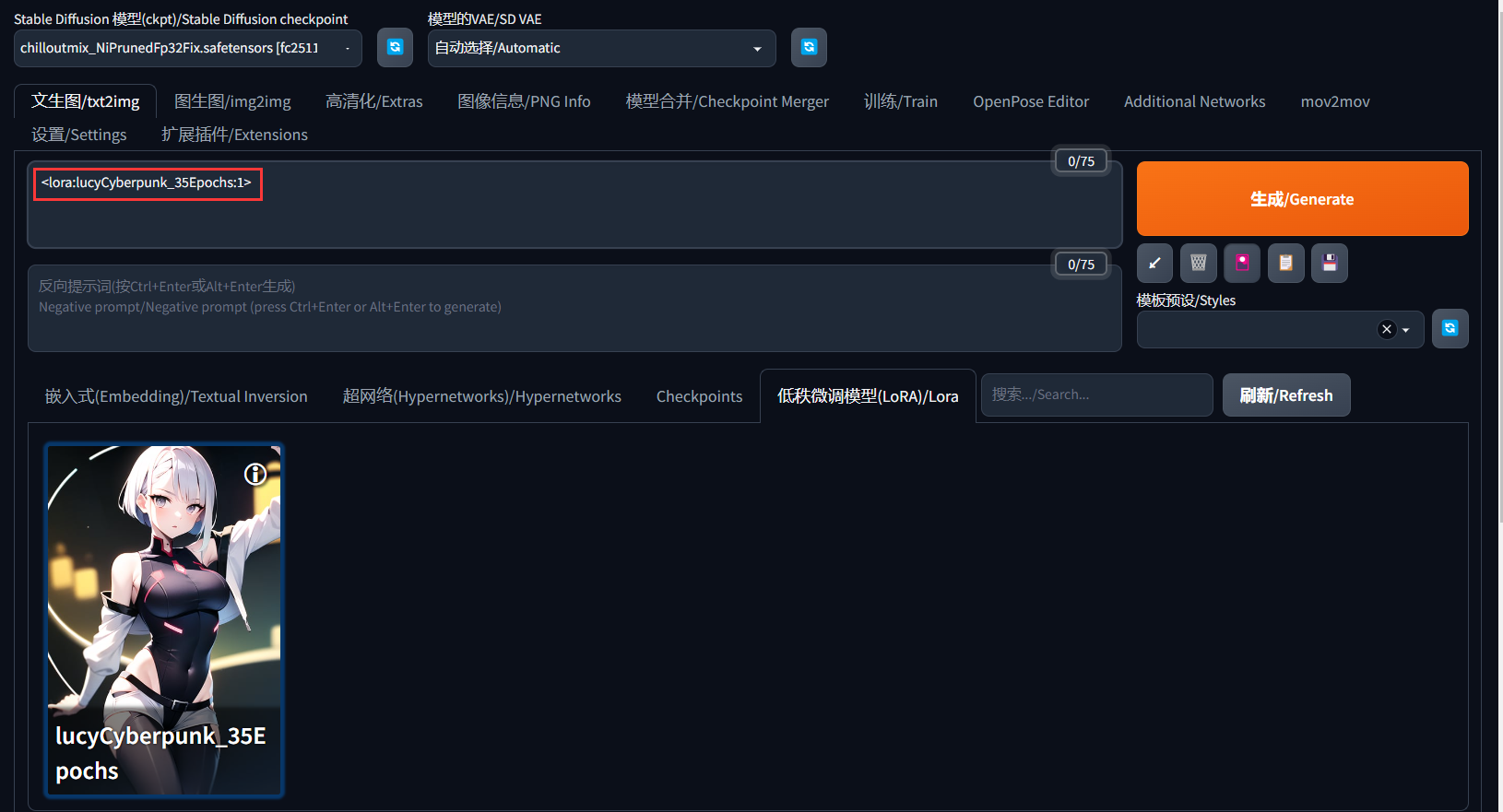
一定要放入指定文件夹中。Lora的使用是调用式的,例如你有Lora模型后,在生成图片时,点击以下lora的模型后,在提示词的信息框中填写这个Lora的描述语,然后你生成的同一张脸或者衣服或其他细节,就会被这个Lora固定住,其他的会变。
在lora模型文件夹中,点击对应的Lora模型后,就会自动填充提示词,也有包含权重值,我们之前说过了,然后你再添加你的关键词进行生成,它就会穿一样的衣服了。我这个是衣服lora模型哦。
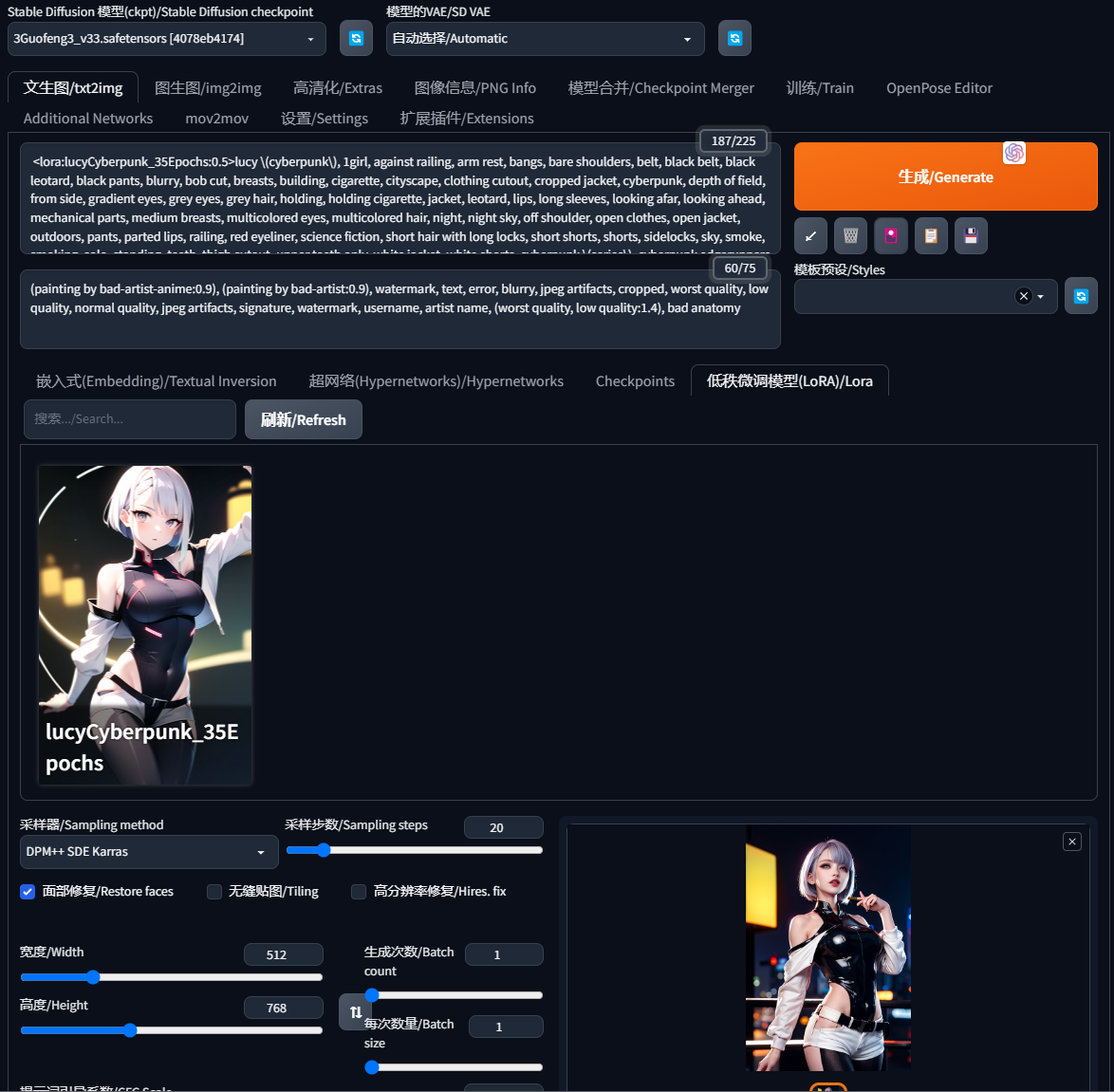

模型管理插件
Lora模型的目录路径是 根目录\models\Lora
如果你没有像我一样的控制面板,请下载模型管理插件
https://github.com/kohya-ss/sd-webui-additional-networks
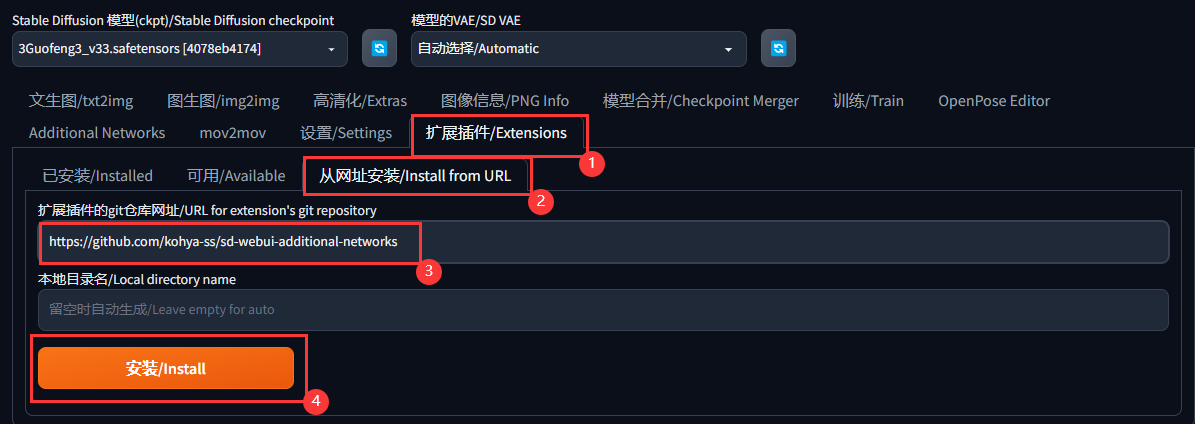
最后应用重启,即可,如下图所示。
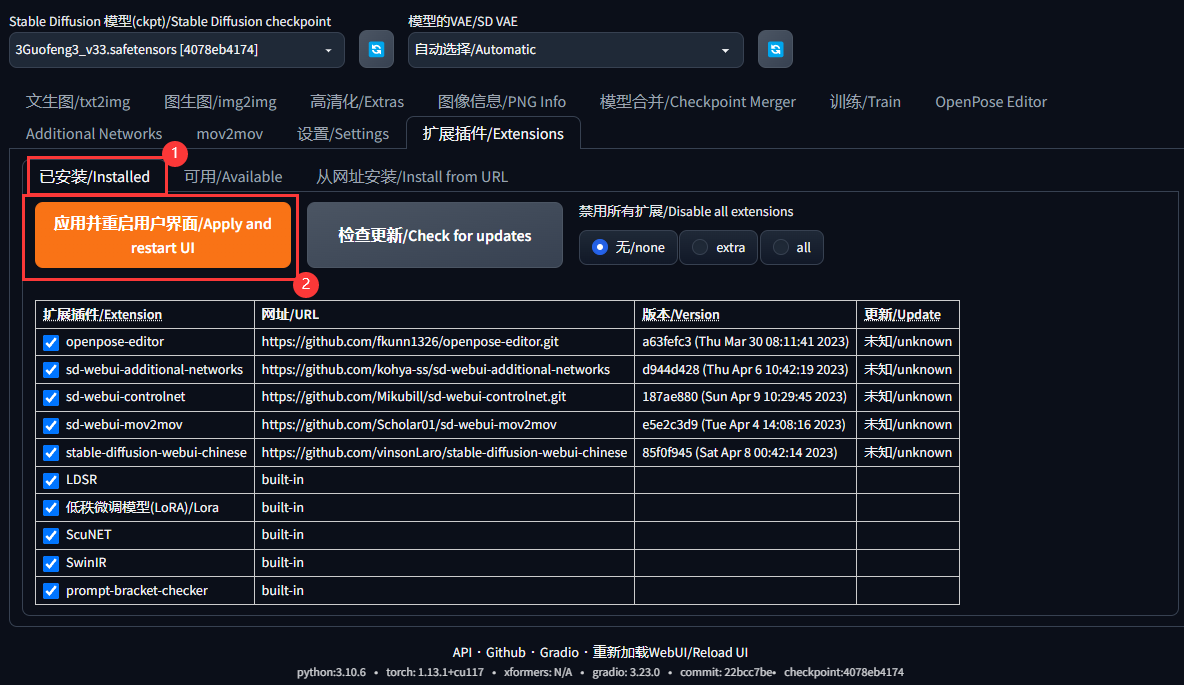
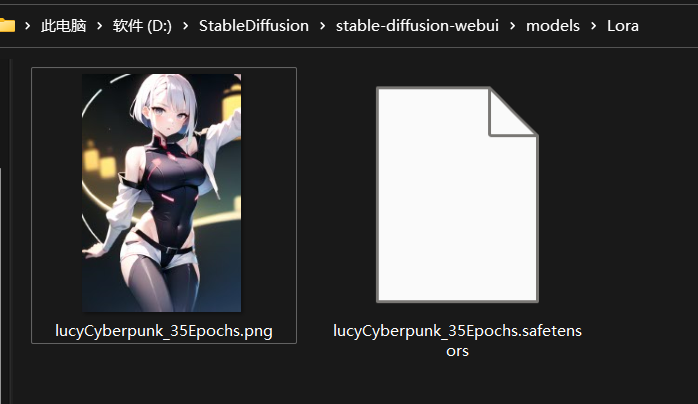
模型缩略图
只要把图片放到和对应模型目录,文件名称一样且png格式即可显示出来。
模型目录总汇
基础模型文件路径 根目录\models\Stable-diffusion
lora模型 根目录\models\Lora
扩展插件路径 根目录\extensions